Monolith vs Microservices: A Real-World Decision Framework

|
Getting your Trinity Audio player ready...
|
If you’ve spent any time in technical leadership, you know this debate never really dies.
Every few months, a new post declares microservices the gold standard. Then, six months later, another one announces a triumphant return to the monolith. Both sides make strong arguments. Both also leave out the part where their “winning” architecture still failed someone else under slightly different conditions.
This guide won’t tell you which architecture is better. That framing is the core problem. Instead, it gives you an honest, practical framework for making the right call — based on what actually happens in production, not what looks good on a whiteboard.
What Is Monolithic Architecture?
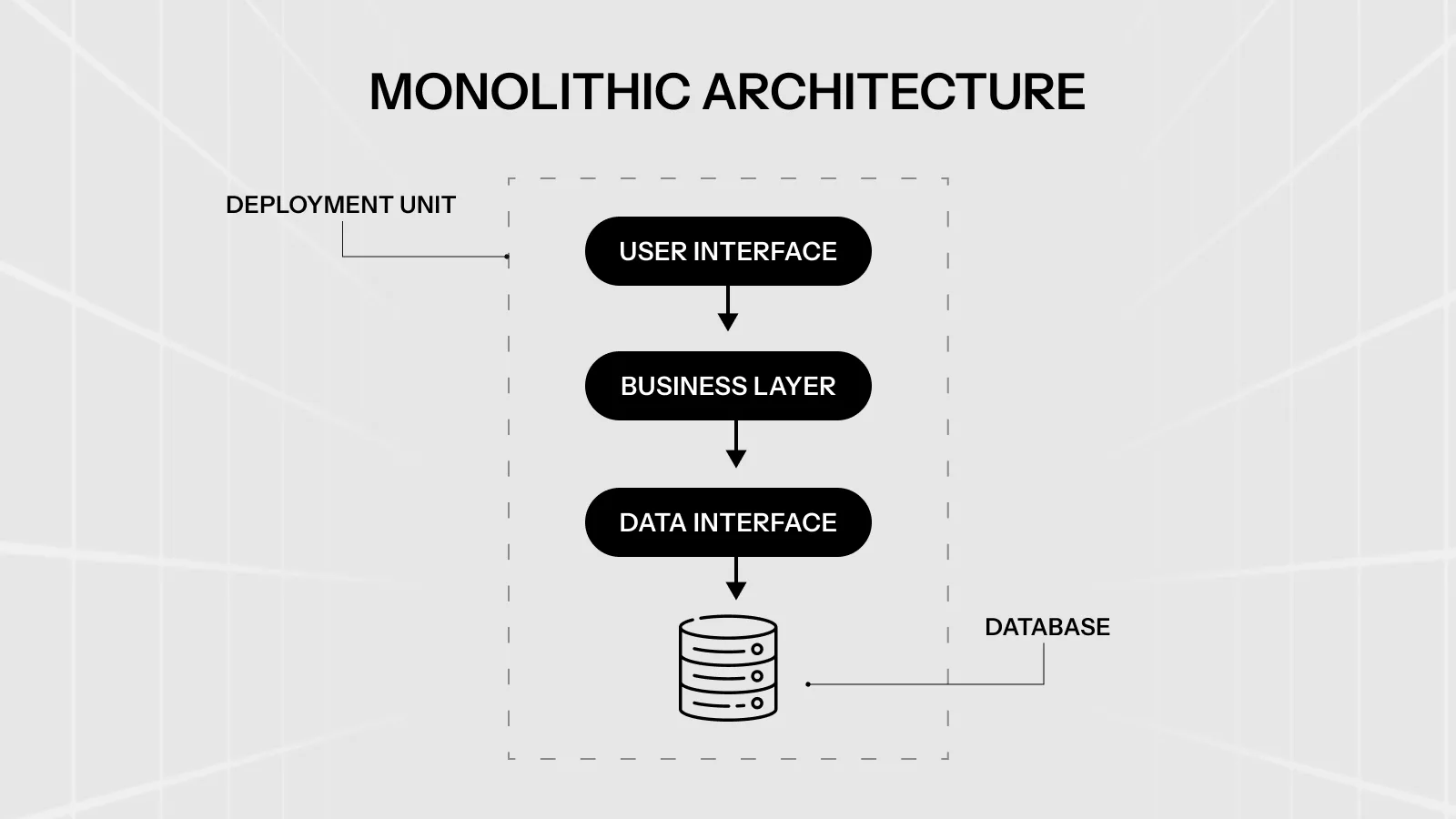
A monolithic application packages everything into one unified codebase. The user interface, business logic, and database layer all deploy together as a single unit.
When you push a change, you’re pushing everything. When something crashes, it can take everything down with it.
That sounds risky — but it’s also what makes monoliths genuinely fast to build. There’s no network hopping between components, no API versioning between services, and no serialization overhead. A function call in a monolith completes in microseconds. Moreover, everything lives in one place, which makes debugging and tracing much simpler.
For teams under ten people building a product that’s still finding its shape, this simplicity is enormously valuable.
When Monoliths Fail
The danger isn’t the architecture itself — it’s neglect. An undisciplined monolith grows into what engineers call a “big ball of mud.” Every change risks breaking something unrelated. Deployment cycles slow to a crawl. No single engineer can hold the full system in their head.
However, that’s not a monolith problem. It’s a discipline problem. A well-structured monolith remains one of the most effective ways to ship software quickly and reliably.
What Is Microservices Architecture?
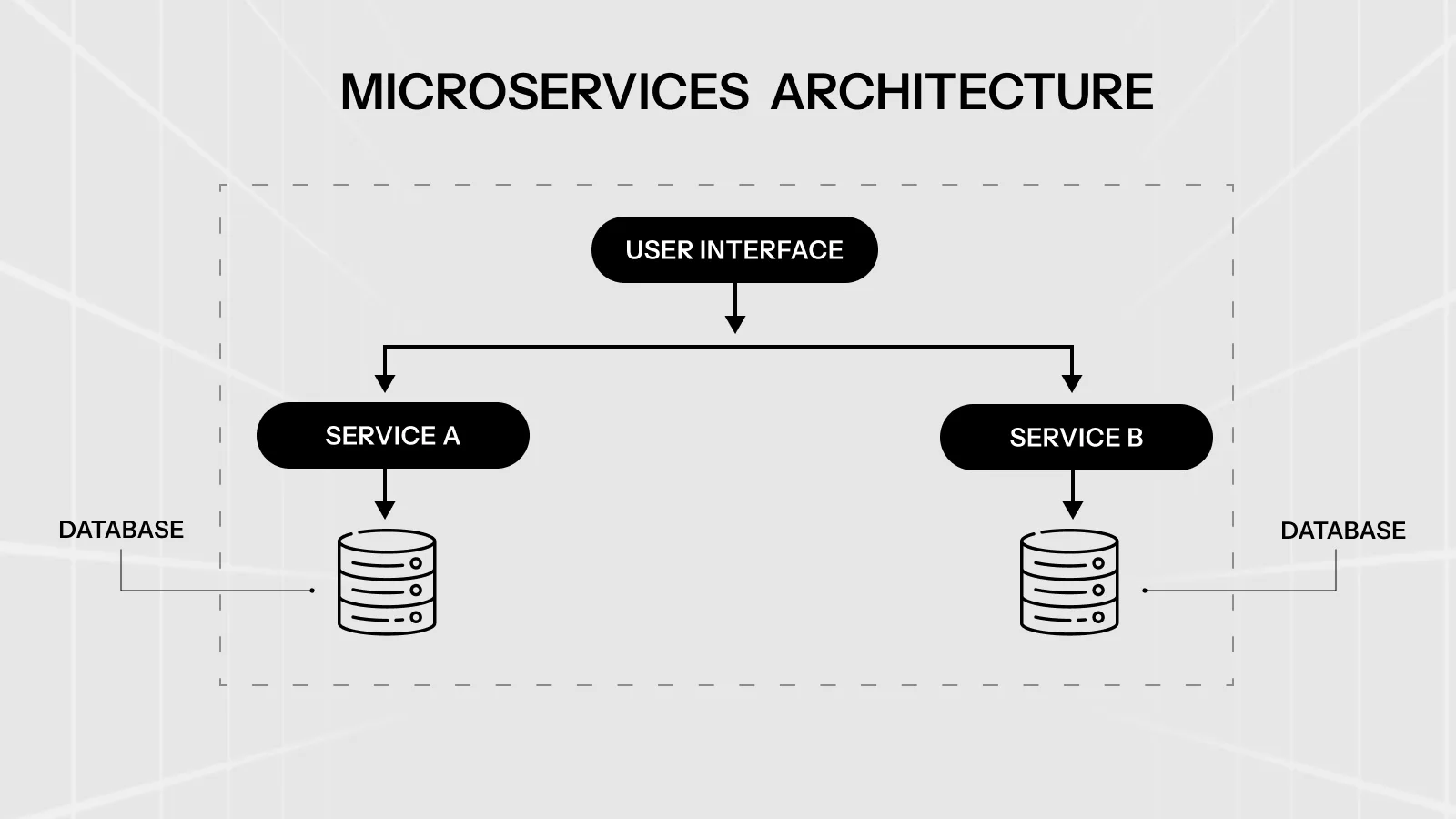
Microservices architecture breaks an application into small, independently deployable services. Each service handles one specific business capability — payments, user authentication, notifications — and owns its own data and logic.
Services communicate through well-defined interfaces, typically REST APIs, GraphQL, or message queues like Kafka or RabbitMQ.
The core promise is autonomy. When your checkout service needs a new feature, you deploy it without touching the inventory service. When your recommendation engine struggles under load, you scale just that component. When one service crashes, the others keep running.
The Real Cost of That Autonomy
In practice, microservices trade one set of hard problems for a completely different set. Furthermore, that new set requires significantly more infrastructure maturity to manage well.
Running 20 microservices means maintaining 20 deployment pipelines, a service mesh, distributed tracing, centralized logging, and an API gateway — before a single feature gets built.
The operational overhead is real. It scales with the number of services, not with traffic volume.
Monolith vs Microservices: A Straight Comparison
Most comparison tables flatten the nuance. Here’s an honest side-by-side view:
| Dimension | Monolith | Microservices |
| Development speed | Fast — no inter-service contracts | Slower up front — API design from day one |
| Deployment | One pipeline, one artifact | One pipeline per service, multiply by N |
| Debugging | Single runtime, simple stack traces | Distributed tracing required |
| Scaling | Scale everything or nothing | Scale individual services independently |
| Fault isolation | One failure can affect all | Failures stay contained per service |
| Team autonomy | Shared codebase, shared bottlenecks | Each team owns their service end-to-end |
| Data management | One database, full ACID transactions | Separate databases, eventual consistency |
| Tech flexibility | One shared stack | Different stack per service |
| Onboarding | One repo to understand | Multiple repos, languages, deployment models |
| Internal latency | Microseconds (in-process) | 10–50ms per network hop |
The Hidden Latency Cost
That latency row deserves a closer look.
In a monolith, a function call takes microseconds. In a microservices system, a single internal HTTP call adds 10–50ms after serialization, network transit, and deserialization. That sounds small — but a single user request can trigger 10 or 15 downstream service calls.
Therefore, you can easily add 200–400ms of pure overhead before any business logic runs. This is exactly why microservices architectures rely heavily on asynchronous communication and event-driven design.
The Real Infrastructure Cost Numbers
Most blog posts skip this. Here’s what the cost picture actually looks like.
A startup running six microservices on Kubernetes might pay $800/month in infrastructure costs. A comparably capable monolith could handle the same load for around $120/month.
At that stage, every dollar matters. The gap is significant.
However, at high scale, the picture shifts. Microservices allow precise, per-component scaling — which reduces waste. A mature system handling millions of users can run cheaper with microservices because you’re only scaling what actually needs to scale.
The decision, therefore, isn’t just about architecture. It’s about where you are in that cost curve.
The Case for Starting with a Monolith
In 2026, the engineering community has reached something close to consensus: unless you have a specific reason not to, start with a monolith.
This isn’t a conservative view. It reflects hard lessons from watching teams spend six months building microservices infrastructure for products that never found product-market fit.
Your Domain Is Still Changing
This is the most underrated argument for monoliths. When you’re building something new, you’re constantly discovering what the application actually needs to do.
Features get added, removed, and restructured. Business logic that seemed clearly separable turns out to be deeply intertwined. Refactoring across a single codebase is straightforward. In contrast, refactoring across service boundaries means changing APIs, updating consumers, versioning contracts, and coordinating deployments.
Martin Fowler — who helped popularize microservices — has been explicit: “You shouldn’t start a new project with microservices.” You need to understand your domain well enough to draw the right service boundaries. You rarely have that understanding at the start.
Small Teams Move Faster in One Codebase
Microservices architecture is fundamentally an organizational solution. It’s designed for large, autonomous teams working in parallel.
If you don’t have large, autonomous teams, the overhead doesn’t pay for itself. A five-person team maintaining eight microservices spends a disproportionate amount of time on infrastructure, deployment tooling, and inter-service debugging — rather than building product.
Moreover, onboarding a new engineer becomes dramatically harder when there are eight separate repos to understand.
Debugging Stays Simple
When something breaks in a monolith, you get a stack trace. You can see exactly what called what, where the error started, and what state the application was in.
In a microservices system, a single user-facing bug might require correlating logs across four services, identifying which network call failed, and determining whether the failure cascaded from upstream.
Teams without mature observability tooling often spend hours debugging what would have been a five-minute fix in a monolith.
When Microservices Architecture Genuinely Makes Sense
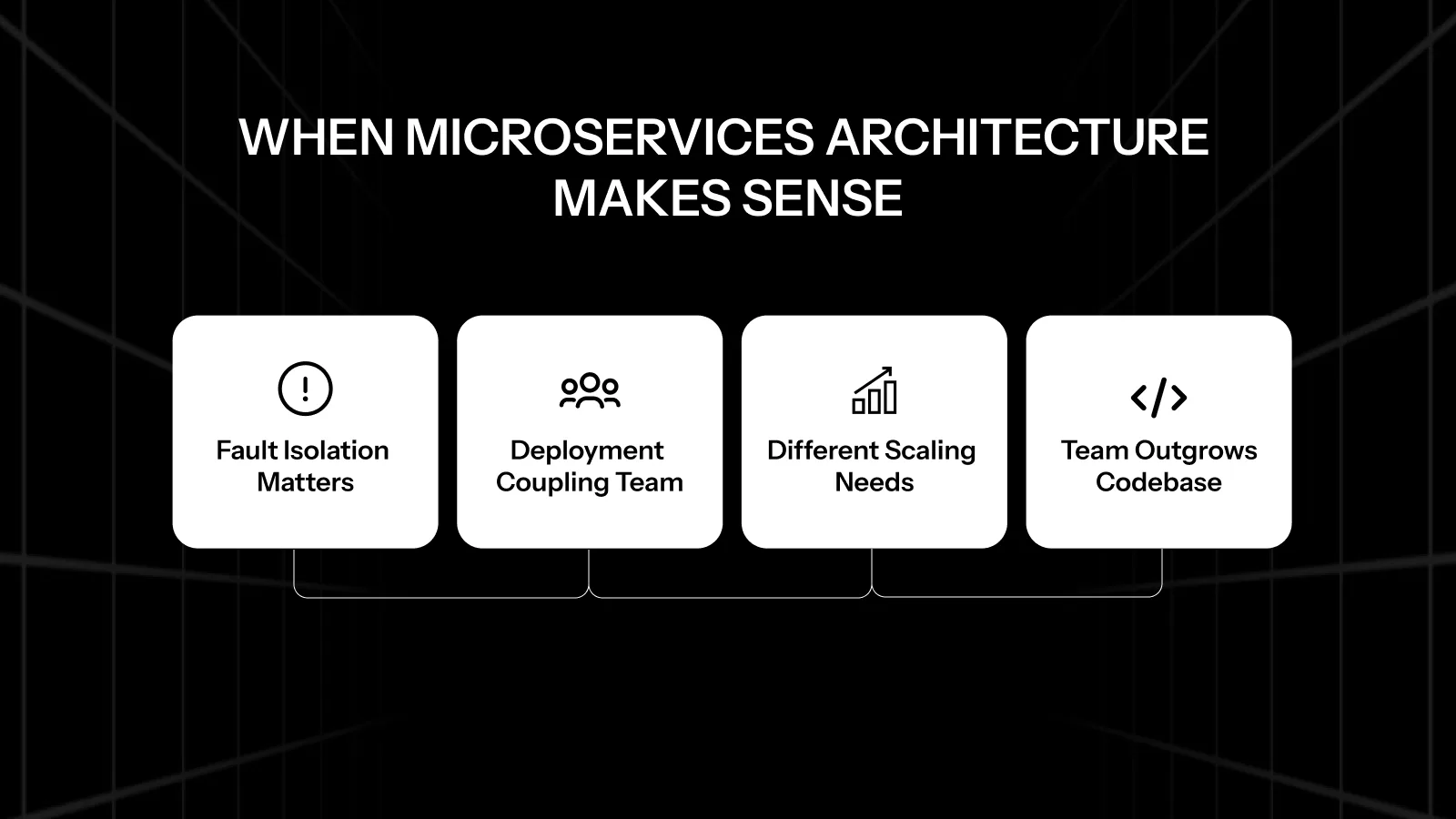
There is a point at which a monolith starts to genuinely limit you. That point is real — even if it’s further out than most teams expect.
Here’s what it actually looks like when you’ve reached it.
Deployment Coupling Is Blocking Teams
The clearest signal isn’t a performance metric. It’s when multiple teams are regularly blocking each other’s deployments.
The payments team can’t ship until the user service team finishes their work. A broken test in an unrelated part of the codebase stops your entire deploy pipeline. A database migration for one feature takes down staging for everyone.
When deployment has become a coordination problem, service decoupling directly solves it. Furthermore, the benefit compounds as your team grows.
Components Have Very Different Scaling Needs
If your video transcoding service needs to burst to 50x capacity during peak hours while your authentication service runs at constant load, scaling them together wastes money.
Microservices allow you to allocate compute exactly where it’s needed. This becomes especially important for AI workloads, which have fundamentally different compute profiles — often requiring GPU instances — that you’d never want to provision for your entire application stack.
Fault Isolation Becomes a Business Requirement
For products where downtime has direct financial consequences — fintech, e-commerce, B2B SaaS with enterprise SLAs — risk concentration in a monolith becomes a real liability.
With well-designed microservices, a failure in the recommendation engine doesn’t affect checkout. A bug in the notification service doesn’t affect user authentication. That isolation can be the difference between a minor incident and a critical outage.
Your Engineering Org Has Outgrown One Codebase
Amazon’s “two-pizza rule” reflects something real. When your engineering organization grows past 20–25 people in a shared codebase, coordination overhead starts compounding fast.
Code reviews become bottlenecks. Merge conflicts multiply. The codebase becomes a coordination problem as much as a technical one. In contrast, microservices — when aligned properly with team boundaries — let each team own their service end-to-end and ship independently.
The Middle Path: The Modular Monolith
The monolith vs microservices debate often skips the most practical option for many companies: the modular monolith.
A modular monolith is a single-deployment application with strict internal module boundaries, well-defined interfaces between modules, and clear separation of concerns. Each module handles a specific business domain — orders, payments, users, notifications — but they all live in one codebase and deploy together.
Why Shopify Still Runs a Monolith
Shopify processes billions of dollars in transactions on a modular monolith architecture. Their engineering team has written publicly about how a well-organized monolith scales further — technically and organizationally — than most companies expect.
The modular monolith gives you most of what teams actually want from microservices: clean boundaries, clear ownership, and independent development within each module. However, it does this without the distributed systems overhead.
In addition, when you do eventually need to extract a service, the clean internal boundaries make migration dramatically easier — because the interfaces are already defined.
The Distributed Monolith: The Anti-Pattern to Avoid
There’s a painful pattern teams fall into when they attempt microservices without a clear domain model — the distributed monolith.
This is when you’ve split code into separate services, but those services remain so tightly coupled — through shared databases, synchronous call chains, and implicit dependencies — that you still have to deploy them together.
The result: all the operational complexity of microservices, none of the independence benefits.
Services that share a database can’t evolve their schemas independently. Services chained in synchronous calls create fragile systems where any single failure propagates everywhere. Debugging becomes extremely difficult.
How to Avoid It
The fix is Domain-Driven Design (DDD). Before decomposing anything, clearly define bounded contexts — what each service is responsible for, what data it owns, and where its boundaries lie.
If you can’t articulate those boundaries cleanly, you’re not ready to decompose. Therefore, pushing ahead without that clarity almost always produces a distributed monolith instead of a real microservices architecture.
The Amazon Prime Video Story: What It Actually Teaches Us
In 2023, Amazon’s Prime Video team published a blog post describing how they cut infrastructure costs by 90% — by moving their video quality monitoring service from a microservices setup back to a monolith.
The story sparked a wave of “microservices are dead” takes. Most of them missed the point.
What Actually Happened
The Prime Video team had built their monitoring tool using AWS Step Functions and Lambda. When they tried to scale it, they hit a wall at roughly 5% of expected load. The Step Functions orchestration became a bottleneck. Constant round-trips to S3 between service calls were generating enormous, unnecessary costs.
Their solution was to consolidate the components into a single process running on EC2 and ECS. By keeping data transfers in memory instead of routing them through S3, they eliminated the overhead entirely.
Importantly, this wasn’t Amazon abandoning microservices as a company. The rest of Prime Video’s infrastructure continued running on a distributed architecture. The Prime Video engineers themselves concluded: “Microservices and serverless are tools that work at high scale, but whether to use them over a monolith has to be made on a case-by-case basis.”
For a tightly integrated processing pipeline where data flows between components at high frequency, in-process communication was simply the right tool for the job.
The Strangler Fig Pattern: How to Migrate Safely
If you’re running a monolith today and the time has come to extract services, the strangler fig pattern is the safest migration path available.
The name comes from the strangler fig tree — a plant that grows around its host and gradually replaces it. The idea is simple: you never do a big-bang rewrite. Instead, you extract services incrementally while the monolith keeps running.
How It Works in Practice
First, identify a self-contained piece of functionality at the edges of your system. User authentication, email notifications, and file storage are common first choices — they have clear inputs and outputs with minimal internal dependencies.
Then extract that piece as a standalone service, route traffic to it through an API gateway, and validate it in production. Once it’s stable, decommission it from the monolith. Then repeat the process, one service at a time.
This approach keeps risk low because the existing system never goes offline during migration. Netflix, Uber, and Amazon all followed variants of this approach — and each migration took years to complete. If someone is pitching a six-month full rewrite from monolith to microservices, be skeptical. Realistic production migrations are measured in years, not sprints.
A 10-Question Decision Framework
Before you commit to either architecture, answer these questions honestly.
- How large is your engineering team? Under 10 engineers → lean toward a monolith. 10–25 → a modular monolith is worth serious consideration. Over 25 with multiple product teams → microservices start making organizational sense.
- Is your product validated and generating revenue? Pre-product-market-fit, your priority is speed to change. Microservices slow that down. Wait until your core domain model is stable before decomposing it.
- Do you have a dedicated DevOps or platform team? Without someone owning CI/CD pipelines, container orchestration, and observability tooling, microservices become a burden your product engineers absorb. This is a prerequisite — not an afterthought.
- Are specific components experiencing uneven load? If the difference is creating real cost or performance problems, targeted scaling starts to justify the added complexity.
- Are teams regularly blocking each other’s deployments? When your deploy pipeline has become a coordination problem, service decoupling directly addresses it.
- How critical is fault isolation to your business? If downtime directly costs revenue or violates SLAs, the resilience benefits of microservices carry real dollar value.
- Is your current monolith well-structured or a mess? A modular, disciplined monolith is not a problem to solve. However, a tangled, undocumented one won’t get better by adding microservices on top of it.
- Can you draw clear domain boundaries before you start? If you can’t clearly define what each service owns, you’ll create a distributed monolith — not a real microservices architecture.
- Do you have observability tooling ready? Distributed tracing, centralized logging, and service health dashboards need to exist before you go live — not after your first incident.
- Are you starting fresh or migrating an existing system? Starting fresh? Begin with a monolith and design for eventual extraction. Migrating? The strangler fig pattern is almost always the right path.
Where the Industry Has Actually Landed in 2026
The architecture conversation has matured considerably. The microservices maximalism of 2018 has given way to something more calibrated.
Several clear patterns have emerged across the industry.
The Modular Monolith Is Back — Officially
The modular monolith has been quietly rehabilitated as a legitimate, production-grade architectural choice. Shopify’s continued success at massive scale has been particularly influential. Kelsey Hightower, one of the most respected voices in cloud-native infrastructure, predicted years ago that teams would eventually realize microservices simply traded one set of problems for another.
He wasn’t wrong.
Platform Engineering Has Emerged as a Discipline
Platform engineering now exists specifically to reduce the operational tax that microservices impose. Internal developer platforms, standardized service templates, and self-service infrastructure tooling are how large engineering organizations make microservices manageable.
However, this capability requires dedicated investment — and most companies underestimate it significantly when they first commit to microservices.
The “Spectrum” View Is Replacing the Binary
In 2026, forward-thinking engineering leaders no longer frame this as a binary choice. Instead, they think in terms of a spectrum — starting with a well-structured monolith, extracting services when there’s a concrete reason to do so, and treating architecture as something that evolves with the organization.
That shift in framing is, arguably, the most important development in this conversation over the past three years.
Final Verdict: Which Architecture Should You Choose?
There is no universally correct architecture. There is only the architecture that fits your current scale, team size, product maturity, and operational readiness.
Start with a monolith if:
- You’re building something new
- Your team is under 10–15 engineers
- Your domain model is still evolving
- You don’t yet have a DevOps function
Move toward microservices when:
- Deployment coupling is actively blocking teams
- Specific components need independent scaling
- Fault isolation has become a business requirement
- Your engineering org has grown past 20–25 people
Consider a modular monolith if:
- You want clean internal ownership without distributed systems overhead
- You’re at the $1M–$50M revenue stage
- You want to keep migration options open without committing to either extreme
The teams that make this work aren’t the ones who choose the “correct” architecture upfront. They’re the ones who build enough discipline into whatever architecture they choose so they can evolve it honestly as their needs change.
That’s the real goal — systems you can change without fear, that serve your users reliably while you’re figuring out everything else.
Unsure which architecture fits your stage? We work with engineering teams at every point in this journey — from early-stage monoliths to large-scale microservices migrations. Book a free architecture review and let’s look at what you’re actually working with.
Not Sure Which Architecture Fits Your Stage?
Stop guessing based on trends. Get a practical, real-world evaluation of your system, team structure, and growth stage—so you can make the right architectural decision with confidence.

Amanjeet Singh
Software Engineer



Explore More Architecture Insights
Deep dives, real-world case studies, and practical frameworks to help you design systems that scale without unnecessary complexity.