Event-Driven Architecture for Modern Web Applications: A Node.js Guide for Senior Engineers

|
Getting your Trinity Audio player ready...
|
There’s a particular kind of pain that hits around the time your monolith starts cracking. A checkout request times out because the email service is slow. A payment fails silently because the inventory service threw an exception nobody caught. You add one new feature, and suddenly three other teams need to redeploy their services. Sound familiar?
This is what tightly coupled, synchronous architectures feel like at scale — and it’s the exact problem that event-driven architecture (EDA) was designed to solve. Rather than services calling each other directly and waiting for a response, they communicate by publishing events. Something happened. Here’s a record of it. Everyone who cares can react in their own time.
That single shift in mindset changes almost everything about how your system behaves under load, under failure, and under the pressure of a growing engineering team. This guide walks through EDA honestly — patterns, trade-offs, Node.js implementation, and the failure modes that most tutorials quietly skip.
What Is Event-Driven Architecture?
Think of EDA like leaving a voicemail instead of calling someone and waiting for them to pick up. You record what happened, drop it in a shared mailbox, and move on. The recipient checks the mailbox when they’re ready and handles it on their end. Neither party has to be available at the same time.
In technical terms, an event is an immutable record that something happened — “OrderPlaced”, “PaymentFailed”, “UserSignedUp”. The service that creates that record is called the producer. The service that reacts to it is the consumer. Sitting in between is a message broker — something like Apache Kafka or RabbitMQ — which stores the event reliably and makes sure the right consumers receive it.
Producer → Message Broker → Consumer(s)
What makes this different from a regular API call is that the producer publishes the event and immediately moves on. It never waits for a consumer to finish. Better yet, multiple consumers can independently react to the same event without the producer knowing anything about them. That’s the loose coupling everyone talks about — and it’s genuinely useful once you’ve felt what tight coupling costs you in a real production incident.
Core Patterns in Event-Driven Systems
EDA isn’t a single pattern. It’s more like a family of related approaches, each one suited to a different kind of problem. Getting clear on which pattern you’re using — and why — saves you from a lot of architectural regret later.
Pub/Sub: One Event, Many Reactions
Publish/subscribe is the pattern most people encounter first. A producer publishes to a topic. Any number of consumers subscribe to that topic and receive the event. The producer never knows — or cares — who’s listening.
This works beautifully for broadcast scenarios. When a user updates their billing address, your notification service needs to send a confirmation email, your fraud detection system wants to flag the change, and your audit log needs a record. All three subscribe to the same user.address_updated topic. None of them depends on the others, and the user service doesn’t need to be modified when a fourth consumer gets added six months later. That’s the kind of extensibility that feels like magic until you’ve experienced the alternative — adding a new if block to a monolithic service and praying nothing breaks.
Event Streaming: The Persistent Log
Event streaming is a step up in power and complexity. Instead of fire-and-forget delivery, events are stored in a durable, ordered log that consumers can read at their own pace — and replay from any point in history.
Apache Kafka is the canonical tool here. When your analytics team wants to rebuild their dashboard from scratch, they replay the log from the beginning. When a new service joins and needs to catch up on three months of order history, it reads from offset zero. When a consumer crashes halfway through processing, it picks up exactly where it left off. This replay capability is the feature that separates event streaming from traditional message queues, and once you’ve needed it in production, you can’t imagine going back.
Event Sourcing: State as a History of Changes
Most databases store the current state of something. Event sourcing stores the history of everything that happened to it, and derives the current state by replaying that history.
Instead of a users table with a status: “suspended” column, you have a stream of events — UserCreated, UserVerifiedEmail, UserSuspended — and the current state is the result of replaying all of them. This gives you a complete audit trail, the ability to reconstruct the state at any point in the past, and a natural fit for CQRS.
Be honest with yourself before choosing event sourcing, though. It’s one of the more intellectually satisfying patterns in software, and that makes it easy to reach for it when you don’t actually need it. Managing schema evolution across a years-long event log, building snapshot strategies to avoid replaying a million events just to get today’s state, handling projections for different consumers — these are real, ongoing engineering costs. Use event sourcing when the audit trail and replay capabilities are genuine business requirements, not engineering preferences.
CQRS: Separate the Read from the Write
Command Query Responsibility Segregation splits your data model into two distinct parts. Writes (commands) go through one path, emit events, and update the write store. Reads (queries) come from a separate model that consumes those events and maintains a structure optimized for how data gets queried.
The payoff is real. Your read model can be a fully denormalized, query-friendly projection while your write model stays clean and normalized. You can scale reads and writes independently. You can have multiple read models optimized for different query patterns — one for full-text search, one for dashboards, one for the mobile API.
The cost is also real. Your read model is eventually consistent with your write model, which means that immediately after a write, a read might return the old data. Most users never notice. Some business flows genuinely can’t tolerate it. Know which situation you’re in before you commit.
An honest note on all four patterns: If you’re building a simple CRUD application, an internal admin tool, or anything that a two-person team maintains, none of this pays off. The operational overhead — running brokers, managing consumer groups, operating a schema registry, debugging offset lag at 2am — is substantial. Don’t adopt it because it looks good on an architecture diagram.
How to Implement Event-Driven Architecture in Node.js
One reason Node.js is a natural fit for event-driven systems is that the runtime itself was built around events. The event loop, the EventEmitter class, the non-blocking I/O model — these aren’t just implementation details. They’re the same mental model as EDA, applied at the process level. While Java or Python can certainly run event-driven workloads, Node.js doesn’t require you to fight the language to do it.
Start Here: Node.js EventEmitter
For decoupling logic within a single service, the built-in EventEmitter is often the right starting point. It’s zero-dependency, trivial to understand, and surprisingly powerful for in-process event handling:
const EventEmitter = require('events');
const eventBus = new EventEmitter();
// Producer: something happened
function placeOrder(order) {
// persist the order first
eventBus.emit('order.placed', { orderId: order.id, userId: order.userId });
}
// Consumer: react to it
eventBus.on('order.placed', async ({ orderId, userId }) => {
await notificationService.sendConfirmation(userId, orderId);
});
The limitation is real but well-defined: EventEmitter only works within a single process. It doesn’t survive a restart and it doesn’t scale across multiple Node.js instances. When you need to cross that boundary — and you will — it’s time for a real message broker.
Scaling Out: Kafka with KafkaJS
The kafkajs library gives you a clean, modern interface to Apache Kafka. Here’s a working producer and consumer that illustrates the key concepts:
const { Kafka } = require('kafkajs');
const kafka = new Kafka({ brokers: ['kafka:9092'] });
const producer = kafka.producer();
const consumer = kafka.consumer({ groupId: 'payment-service' });
// Publishing an event from the Order Service
async function publishOrderPlaced(order) {
await producer.connect();
await producer.send({
topic: 'order.placed',
messages: [{
key: order.id, // partition key — critical for ordering
value: JSON.stringify(order),
}],
});
}
// Consuming events in the Payment Service
async function startConsumer() {
await consumer.connect();
await consumer.subscribe({ topic: 'order.placed', fromBeginning: false });
await consumer.run({
eachMessage: async ({ message }) => {
const order = JSON.parse(message.value.toString());
await processPayment(order);
},
});
}
Pay attention to the key field. It controls which Kafka partition a message goes to, and Kafka guarantees ordering within a partition. If all events for a given orderId share the same key, they’ll always be processed in order by the same consumer instance. Without that key, you have no ordering guarantee at all.
End-to-End Example: E-Commerce Order Processing
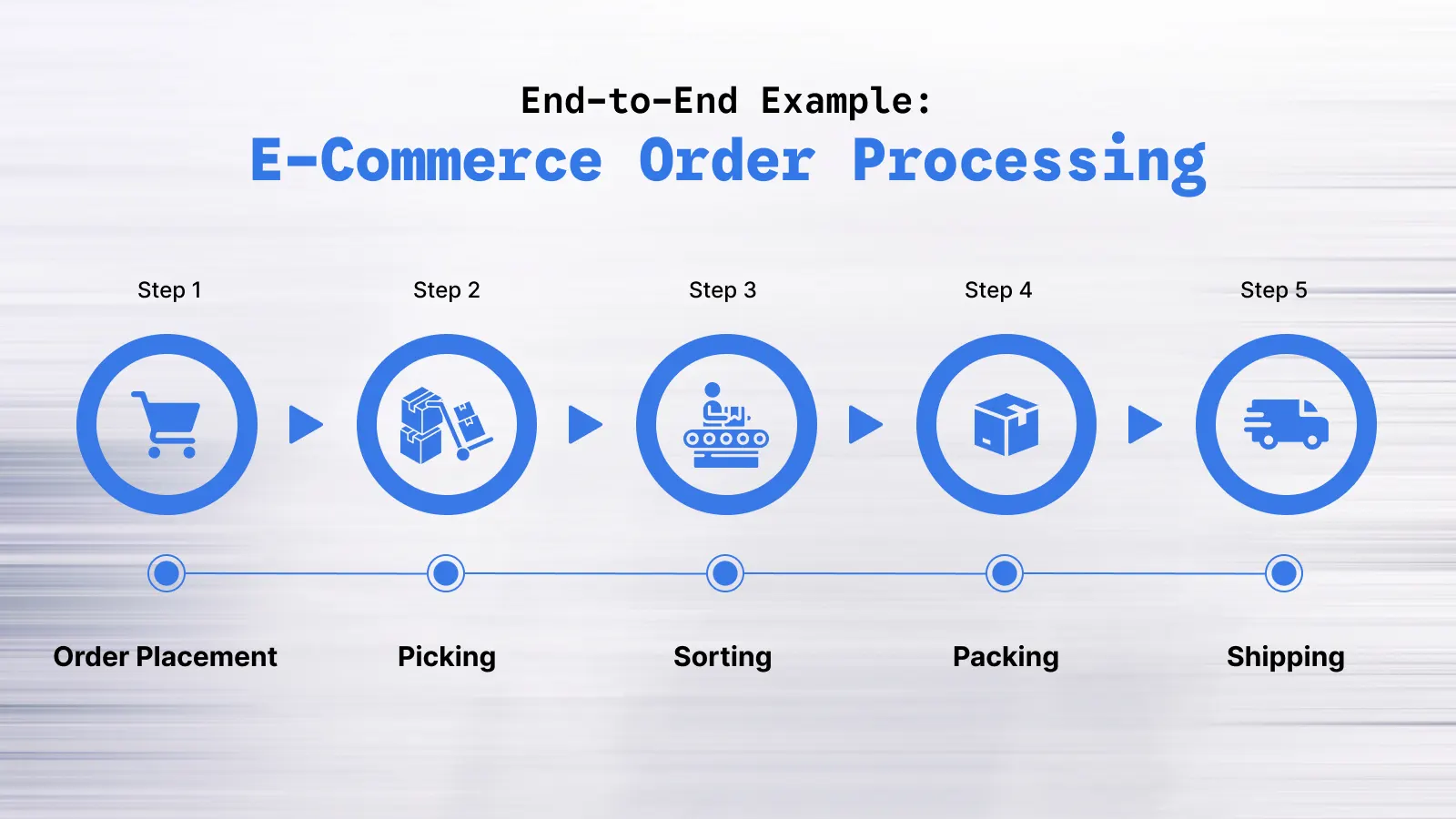 Theory only goes so far. Let me walk through a concrete system — a simplified e-commerce order flow — that shows how these pieces actually fit together in production.
Theory only goes so far. Let me walk through a concrete system — a simplified e-commerce order flow — that shows how these pieces actually fit together in production.
The Event Flow
Customer places order
↓
[Order Service] → publishes "order.placed" to Kafka
↓
[Payment Service] ← subscribes to "order.placed"
→ processes charge
→ publishes "payment.completed" or "payment.failed"
↓
[Notification Service] ← subscribes to both events
→ sends confirmation or failure email
Order Service: Publishing the Event
async function createOrder(orderData) {
const order = await db.orders.create(orderData);
await kafkaProducer.send({
topic: 'order.placed',
messages: [{
key: order.id,
value: JSON.stringify({
orderId: order.id,
userId: order.userId,
amount: order.totalAmount,
timestamp: new Date().toISOString(),
}),
}],
});
return order;
}
Notice that the Order Service doesn’t call the Payment Service. It doesn’t wait for anything. It publishes a fact — an order was placed — and its job is done.
Payment Service: Consuming and Reacting
await consumer.run({
eachMessage: async ({ message }) => {
const { orderId, userId, amount } = JSON.parse(message.value.toString());
try {
const result = await chargeCustomer(userId, amount);
await kafkaProducer.send({
topic: 'payment.completed',
messages: [{ key: orderId, value: JSON.stringify({ orderId, transactionId: result.id }) }],
});
} catch (error) {
await kafkaProducer.send({
topic: 'payment.failed',
messages: [{ key: orderId, value: JSON.stringify({ orderId, reason: error.message }) }],
});
}
},
});
How Failures Become Events
The detail worth highlighting here is what happens when payment fails. The Payment Service doesn’t swallow the error silently. It doesn’t try to call the Order Service back to report the failure. Instead, it publishes a payment.failed event — a first-class fact that something went wrong — and lets the rest of the system react to it independently.
The Notification Service subscribes to payment.failed and sends the appropriate customer email. An internal monitoring service subscribes to the same event and fires a PagerDuty alert if the failure rate climbs above a threshold. A reconciliation service subscribes and marks the order as unpaid so a retry can be scheduled. None of these services knew about each other when the Payment Service was written. That’s the extensibility that makes the investment worthwhile.
Real-World Examples of Event-Driven Architecture
Netflix and Uber get cited constantly in these conversations, and for once the hype is actually earned.
Netflix handles an enormous volume of user activity events — every play, pause, seek, rating, and search — flowing through Apache Kafka into dozens of downstream systems simultaneously. Recommendation models, billing pipelines, A/B testing frameworks, and analytics dashboards all consume from the same event streams. Because none of these systems sits in the critical path of the playback experience, a bug in the recommendation model doesn’t delay video loading for anyone. That kind of fault isolation is extremely difficult to achieve with synchronous service calls.
Uber uses event streaming to coordinate its real-time dispatch system. Driver location updates arrive continuously, trip status changes propagate across services, and surge pricing calculations run independently of the dispatch logic. Because each of these concerns is decoupled through events, Uber’s engineers can deploy a change to the surge pricing algorithm without touching — or redeploying — the dispatch service. That independent deployability is one of the most underappreciated advantages of EDA in a large organization.
Advantages and Disadvantages of Event-Driven Architecture
Let’s be honest about both sides here, because the honest version is more useful than the marketing version.
What You Actually Gain
Scalability that makes sense. When your notification service falls behind during a traffic spike, you add more consumer instances to the same consumer group. Kafka distributes partitions across them automatically. The order service — and every other service — never feels the load. You scale the bottleneck, not the whole system.
Loose coupling that survives team growth. Services communicate through an event contract, not through direct API calls. That means you can replace, rewrite, or upgrade a consumer service without touching the producer. When you have five teams working on different services, that separation becomes the difference between moving fast and spending every sprint coordinating deployments.
Extensibility you don’t have to plan for. Adding a new consumer to an existing topic requires exactly zero changes to the producer. Six months after launch, when the business decides it wants a loyalty points system that reacts to every purchase, you subscribe a new service to the order.placed topic and you’re done. The order service doesn’t know and doesn’t care.
What It Actually Costs You
Debugging is genuinely harder. A synchronous HTTP call fails loudly, immediately, and right in front of you. An event-driven failure fails silently, potentially hours later, in a service two hops away from where the problem started. Without distributed tracing and structured logging set up from day one, debugging these systems is a painful exercise in grep and guesswork.
Event ordering is tricky. Kafka guarantees ordering within a partition. It guarantees nothing across partitions. RabbitMQ with competing consumers guarantees nothing at all. Systems that depend on strict ordering need careful partition key design and, sometimes, additional coordination mechanisms that add complexity you didn’t budget for.
Eventual consistency catches teams off guard. After a write, your read model might return stale data for a short window. Most users never notice. But some business flows — “I just updated my address, now show me the updated address” — can surface this as a confusing, hard-to-reproduce bug. Know your consistency requirements before you commit to CQRS.
Event-Driven Architecture vs REST API
The question isn’t which one is better. It’s which one is right for this specific communication pattern.
| Dimension | REST API | Event-Driven Architecture |
| Communication style | Synchronous request/response | Asynchronous, fire-and-forget |
| Coupling | Tight — the caller knows the callee | Loose — the producer doesn’t know consumers |
| Latency | Low, immediate response | Higher, eventual processing |
| Best fit | Read-heavy, user-facing APIs | Write-heavy, background workflows |
| Failure behavior | Caller sees the error immediately | Consumer retries independently |
| Debugging | Straightforward request tracing | Requires distributed tracing tools |
In practice, production systems use both. REST handles user-facing reads where immediate, consistent responses matter — GET requests, search results, profile pages. EDA handles the write side and all background processing — payment charging, email delivery, analytics ingestion, inventory updates. The boundary between them is usually the response you send to the user: once you’ve confirmed receipt and returned a 200, everything else can happen asynchronously.
Failure Modes in Event-Driven Systems
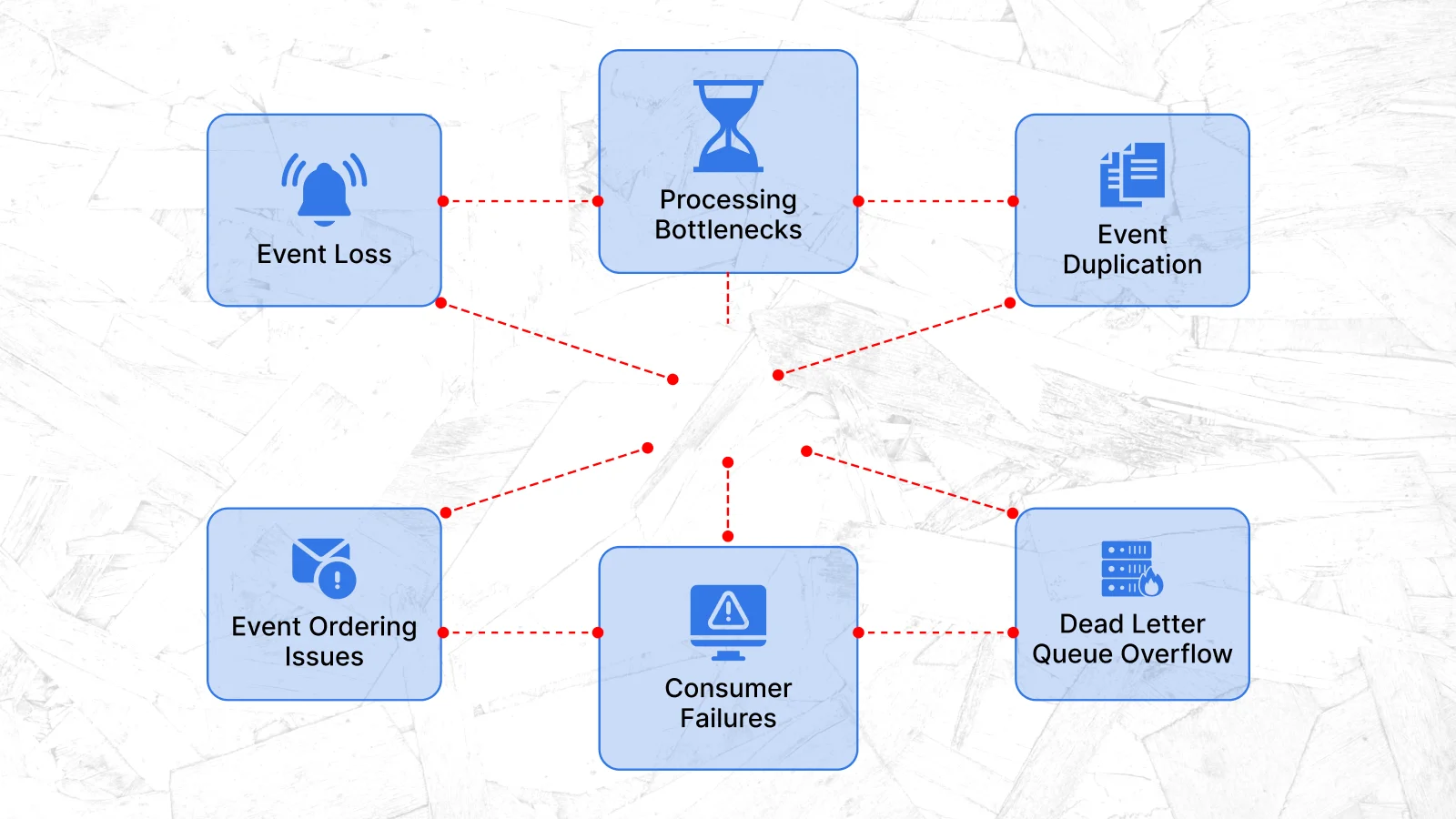
This section is where most tutorials quietly stop. Let’s not do that, because these failure modes will find you in production whether you understand them or not.
Duplicate Events Are Inevitable
Network retries, consumer crashes, and Kafka rebalances can all cause a consumer to process the same message more than once. This isn’t a bug — it’s a documented characteristic of at-least-once delivery semantics. Design for it from the start.
The solution is idempotency: make every consumer handler produce the same result whether it runs once or ten times. Practically, this means using the event’s unique ID as a deduplication key. Rather than blindly inserting a payment record on every run, use something like INSERT INTO payments (id, …) VALUES (…) ON CONFLICT (id) DO NOTHING. The extra constraint costs almost nothing and saves you from double-charging customers.
Events Can Be Lost at the Seam
There’s a dangerous window between writing to your database and publishing to the broker. If a producer persists an order record and then crashes before publishing the event, that event is gone. The order exists in the database but no downstream service will ever know about it.
The solution is the Transactional Outbox pattern. Write both the business record and the outgoing event to the same database, in the same transaction. A separate background process reads from the outbox table and publishes events to the broker. Now your write and your publish are atomic, and nothing gets lost in the gap.
What Happens When Consumers Fail
When a consumer throws an unhandled exception, you have two bad options if you haven’t prepared: silently discard the message, or block the entire consumer waiting for a retry that keeps failing. Neither is acceptable.
The right answer is a dead-letter queue (DLQ). Configure your consumer to retry a message a defined number of times with exponential backoff, and then route it to the DLQ if it still fails. Crucially, monitor that DLQ. A spike in DLQ depth is almost always the first operational signal that a downstream dependency is broken — a database that went down, a third-party API that started returning errors, a schema change that a consumer wasn’t prepared for.
Observability and Monitoring
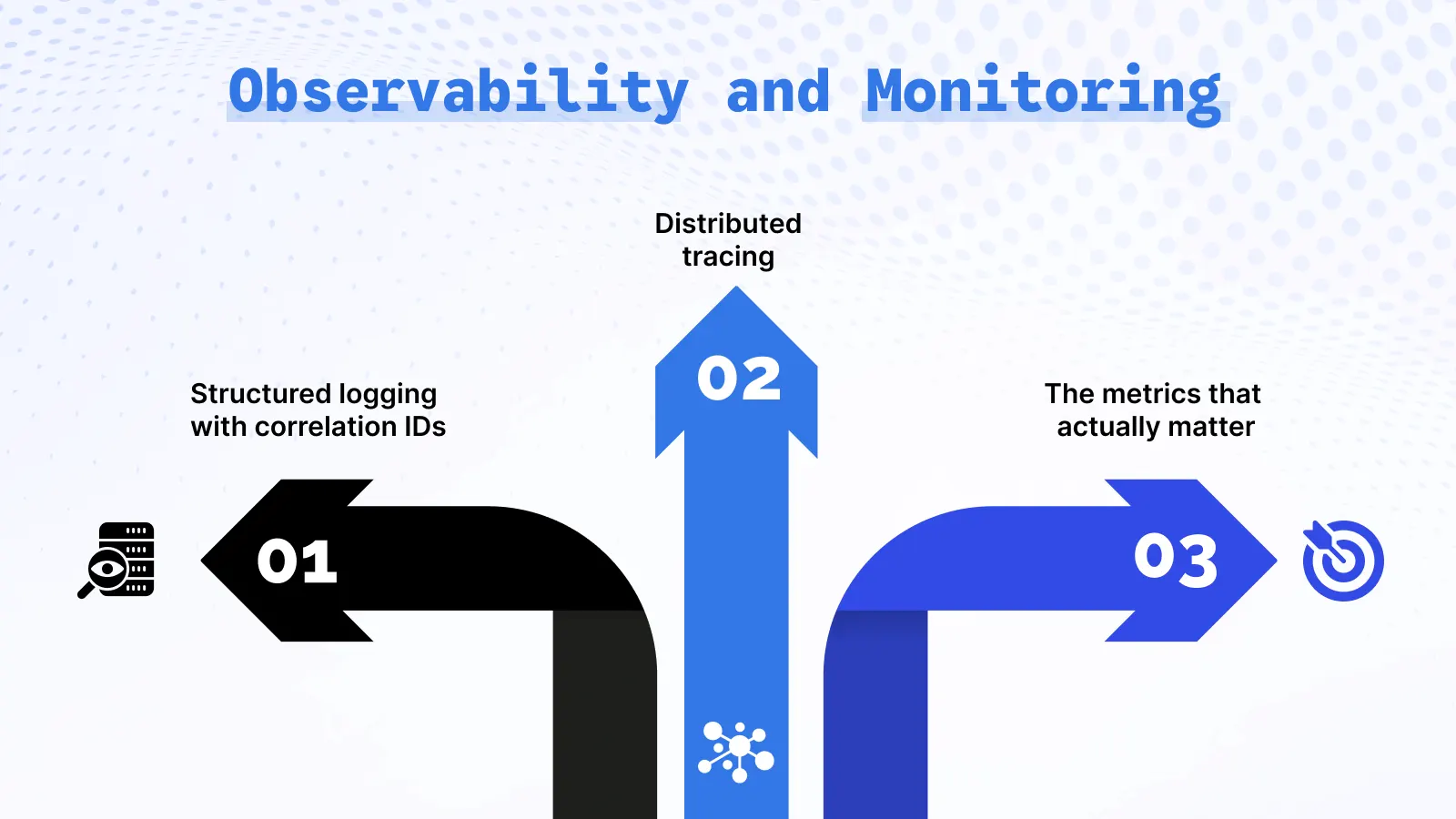
Running an event-driven system without observability is like driving at night without headlights. You might be fine, but you have no idea what’s in front of you until you’re already in it.
Structured logging with correlation IDs is the baseline. Every log line should include a correlationId that was attached to the original event. When a payment.failed event triggers an alert and you need to trace back to the original order, you should be able to filter your log aggregator by a single ID and see the entire journey across every service that touched it. This is not hard to implement, but it requires discipline to do it consistently from the start.
Distributed tracing takes this further. Tools like OpenTelemetry let you visualize the full span of processing across services — how long the Order Service took to publish, how long the message sat in Kafka, how long the Payment Service spent charging the card. The important implementation detail is that your Kafka consumer should extract the trace context from the message headers and continue the existing span, rather than starting a new root trace. Without that, your traces will be fragmented and much less useful.
The metrics that actually matter in a live event-driven system are consumer lag, throughput, error rate, and DLQ depth. Consumer lag — how far behind a consumer group is from the latest offset — is the most important one to watch. A steadily rising lag means your consumers can’t keep up with producers, which eventually shows up as delayed notifications, stale data, and unhappy users. Set an alert on it before you go live.
Best Practices for Event-Driven Systems
A few practices consistently separate the systems that hold up under pressure from the ones that become maintenance nightmares eighteen months in.
Treat event schemas like API contracts. Once a consumer depends on an event’s structure, you can’t freely change it without breaking that consumer. Use a schema registry — Apache Avro with the Confluent Schema Registry is the standard — and version your schemas from day one. Additive changes (adding optional fields) are generally safe. Removing fields or changing types requires a versioned topic and a coordinated migration plan. This discipline feels unnecessary early and feels essential after the first time you accidentally break three services with a schema change.
Design every consumer to be idempotent by default. As discussed above, duplicate delivery will happen. Don’t treat idempotency as an edge case to handle when it comes up — treat it as a baseline requirement for every handler you write.
Keep your events small and focused. An event should describe one thing that happened, not bundle the entire current state of an object. “Fat events” that carry every field of an entity are tempting because they save consumers a database lookup, but they create a hidden coupling: consumers now depend on the producer’s data model rather than just the event contract. Include the minimal context needed for consumers to act, and let them fetch additional data if they need it.
Test your failure paths, not just the happy path. Unit tests almost never cover what happens when a consumer crashes halfway through processing, when the schema validation fails, or when the DLQ starts filling up. Write integration tests that simulate these scenarios deliberately. The first time you discover a gap in your failure handling should be in a test environment, not during a production incident.
When to Use Event-Driven Architecture: A Decision Framework
Here’s a practical framework for making the call. Not every system needs EDA, and knowing when to say no is just as important as knowing when to say yes.
| Scenario | EDA a good fit? | Why |
| Background job processing | ✅ Yes | Decoupling and retry built in |
| Multiple services react to the same action | ✅ Yes | Pub/sub scales this cleanly |
| High-throughput real-time data pipeline | ✅ Yes | Streaming handles the volume |
| Audit trail is a hard business requirement | ✅ Yes | Event sourcing is the natural fit |
| Simple CRUD with immediate user response | ❌ No | REST is simpler and more than sufficient |
| Strong consistency is non-negotiable | ❌ No | Eventual consistency is unavoidable in EDA |
| Small team, low traffic, early stage | ❌ No | Operational overhead outweighs every benefit |
| Synchronous user-facing reads | ❌ No | REST gives lower latency and simpler guarantees |
The rule of thumb that has held up for me: reach for EDA when you have a genuine, specific need for asynchronous processing, independent scalability, or multiple consumers reacting to the same fact. Avoid it when you’re solving a problem that a well-structured REST API already handles well.
Production Checklist
Before you flip the switch on a live event-driven system, walk through these. Each item has bitten someone in production.
- [ ] Retry with exponential backoff — transient failures retry automatically without hammering a struggling dependency
- [ ] Dead-letter queue configured — failed messages land somewhere after max retries, not in the void
- [ ] DLQ alert set up — you hear about DLQ depth spikes before users do
- [ ] Consumer handlers are idempotent — duplicate processing produces no side effects
- [ ] Schema registry in use — event schemas are versioned and enforced at publish time
- [ ] Transactional outbox pattern implemented — events can’t be lost between DB write and broker publish
- [ ] Distributed tracing instrumented — correlation IDs propagate through message headers across every service
- [ ] Consumer lag is monitored — alert fires before lag causes user-visible delays
- [ ] Event replay has been tested — you’ve actually run a replay in a staging environment, not just assumed it works
- [ ] Graceful shutdown is implemented — consumers finish in-flight messages before the process exits
Conclusion
Event-driven architecture earns its place in systems where tight coupling, synchronous bottlenecks, and the coordination overhead of direct service calls have become real problems — not theoretical ones. When you genuinely need services to scale independently, when multiple teams need to extend behavior without coordinating deployments, or when you need reliable background processing at scale, EDA pays back its complexity cost.
But the complexity cost is real. Distributed tracing, schema management, idempotency, consumer lag monitoring, dead-letter queues — none of this comes for free. The teams that succeed with EDA are the ones who invest in observability early, design for failure from the start, and resist the temptation to use the pattern just because it sounds architecturally sophisticated.
For Node.js specifically, the ecosystem is genuinely excellent. The path from EventEmitter for in-process eventing to kafkajs for distributed streaming is well-trodden, the tooling is mature, and the community has documented the failure modes thoroughly. If your system needs what EDA provides, Node.js is a solid platform to build it on.
Ready to Build Smarter Scalable Systems
From modern web architecture to performance-driven development, we help businesses create resilient digital solutions built for growth.

Amandeep singh
Custom Software Developer



Related Insights & Architecture Guides
Explore expert articles on scalable backend systems, Node.js development, microservices, cloud-native applications, and modern software architecture best practices.


Frequently Asked Questions

What is event-driven architecture in simple terms?
An event is emitted by a producer to a message broker such as Kafka or RabbitMQ. The broker stores the event in a durable manner and provides it to all the subscribed consumers. Every consumer interprets the event in his or her own way and speed. Since the producer does not need any consumer to complete, the entire system remains sensitive even when some individual services are slow or unavailable.
How does event-driven architecture work?
A producer emits an event to a message broker like Kafka or RabbitMQ. The broker stores the event durably and delivers it to all subscribed consumers. Each consumer processes the event independently and at its own pace. Because the producer doesn’t wait for any consumer to finish, the whole system stays responsive even when individual services are slow or temporarily unavailable.
Why is Node.js a good fit for event-driven systems?
This is because Node.js was designed around an event loop and non-blocking I/O, which implies that the architectural model and the runtime model go hand in hand. It does not block an I/O waiting thread and is therefore effective at supporting many events running concurrently. Top of that, its native EventEmitter class and maintained libraries such as kafkajs to Kafka and amqplib to RabbitMQ provide you with good tooling at all levels of the stack.
When should you use event-driven architecture?
Apply it when there is a need amongst two or more services to respond to the same action, when you require asynchronous background processing with high reliability, when autonomous scaling of individual components is important or when an event sourcing can be used as a real business requirement. Use it only with simple CRUD APIs, small applications, or any application where strong immediate consistency is actually needed.
What are the main disadvantages of event-driven architecture?
It is more difficult to debug – failures are not obvious, asynchronous and are many hops away at different points of origin. Eventual consistency may manifest itself as baffling bugs in flows that require immediate read-after-write consistency. The order of events is not universal. And the overhead of operation, to run brokers, maintain schema registries, check the lag of consumers, is high and constant.
Event-driven architecture vs REST API — which one should I use?
Both of them are not universally right – they address various issues. REST would be the appropriate one when it comes to synchronous and user-facing reads where a consistent and immediate response is important. EDA is appropriate to use in asynchronous background workflows, write-intensive processing, and cases where multiple services need to respond to the same fact independently. Both are used in most production systems of any significant scale.
What is Apache Kafka, and why does it matter in event-driven architecture?
Kafka is a message streaming system that is distributed, fault-tolerant. It logs events in a permanent, chronological, history that can be re-read at any historical time. In an event-based system, it is the core, taking events produced by producers and storing them with reliability and then serving them on demand to groups of consumers at their rate. Its main strengths are very high throughput, long-lasting storage (events are not lost once they are consumed), and the possibility of adding new consumers to old topics without any producer modification.
How do you handle failures in event-driven systems?
Its primary mechanisms are: retry logic with exponential backoff on transient failures, dead-letter queues on those messages that fail after a certain number of retries, and idempotent consumer handlers to ensure that there are no harmful side effects to processing the same message twice. The outbox transactional model manages the producer side of the system – that is, events are never lost without a database write and a broker publish.
How do you ensure data consistency in event-driven systems?
You do not have complete consistency – EDA is eventually consistent by definition, and that is not a bad thing at all in the workloads it is meant to be able to handle. In order to address the trade-off: apply the transactional outbox pattern to ensure at-least-once delivery, construct idempotent handlers to ensure that duplicate processing is safe, apply distributed tracing to identify gaps and delays and draw your consistency boundaries carefully so that components of the system that actually need strong consistency continue to apply synchronous patterns.